Sample data and how to improve its accuracy
Sample data is a small subset of the entire data set of subjects being studied. It is easier to work with a small subset which is representative of the entire population of the subjects. Sample data needs to be collected to analyze a situation in order to help gain insights and understand implications of decisions. It is important to conduct such a study, on a small or large scale, before solutions can be offered or new products launched. Analysis based on sample data helps test complex markets, and even helps with simple decisions such as:
- Is it better to start a business straight out of school/college or to work for another company?
- Does taking a loan from a third party pose less risk than borrowing from friends and family?
- Will it be easier to design a product for only a certain demographic, or make it generic?
- Is there a need for the planned product/service?
- What is the best way to market a service?
- What type of competition is out there against the planned product/service?
- How can the traffic pattern be improved to accommodate a new school in the neighborhood?
These are just a few examples of the type of questions that could be better answered if backed with good analysis based on an accurate and precise data set.
Sample data can be collected in one of two ways – randomly or selectively.
Random data is picked without any consideration, at random as the term suggests. Such random data sets are most common and probably more accurate to answer generic questions. Examples of random data will be a set of names picked from a hat; 5 cards being picked from a set of playing cards by a blindfolded person; tossing a coin for a random result. There is a random data generator website available for use for free.
Selective/targeted data sets are appropriate when designing a product or service for a target market. For example, when designing an app for young people, the data set must be drawn from within the target age range. Another example would be marketing a luxury brand to affluent people, requiring sample data to be drawn based on the income levels.
Once a decision has been made as to the approach to select data, the next step is to ensure that the data is picked with accuracy and precision, leading to analysis results that are reliable. Accuracy refers to how close data points are to the true value, whereas precision is how close the data points are to one another.
Accuracy of data means it is consistent and falls within an expected average or format, deeming it reliable. A common example of data accuracy will be a consistent date format, whether collected from a U.S. source or a European source. If collecting from both sources, data will need to be represented in a consistent chosen format, say MM/DD/YYYY. Another example would be measuring the income level of a set of people living in an affluent neighborhood. Data points will fall within an expected band of income level to be accurate.
Data standardization rules and strict data quality checks can be put in place to ensure data accuracy, since inaccurate data can lead to issues like wrong dates being interpreted leading to missed meetings and deadlines; or the wrong sales goals; or wrong medication given on wrong days.
Precision of data refers to variability of the data from the expected band of accuracy. Data may be accurate but it may not be precise if the data points are not close to each other or erratic. If the same data can be reproduced or repeated with low random errors then it is considered to have high precision. An example of precise data is measuring income levels repeatedly and finding similar data each time.
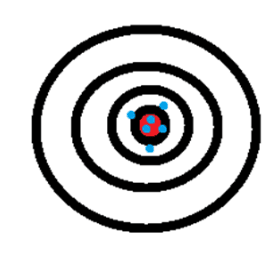
The best way to visually show accuracy and precision is on a dartboard where arrows that are accurate fall close to the bullseye in the center and arrows that are precise fall close to one another.
Image 1 depicts accurate data aiming for the center, though NOT precise as the arrows are all over

Image 2 depicts precise data in a close cluster, however NOT accurate as they miss the center
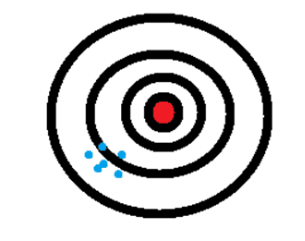
Image 3 depicts both accurate and precise data as the arrows are falling around the center, and close together
How to improve the accuracy and precision of sample data
It is crucial for big conglomerates, supply chains, manufacturers, and service providers to have accurate sample data to conduct their analysis and suggest remedies to problems such as how to ease traffic patterns in inner cities.
Inaccurate data that is inconsistent or not indicative of the population it represents can lead to expensive mistakes.
Data accuracy can be achieved by following these practices:
- Appropriate channels must be sought after to gather relevant data.
- If using third parties for data feeds, those companies must be vetted for past performance, customer satisfaction, and industry reputation.
- Random sampling must be properly carried out for fairness and equal representation. A good way to achieve this would be to divide the population into similar pockets, then take a sample from each pocket.
- Biases need to be avoided when collecting data. Ensure that availability of the sample population, timing, language barriers, and viewpoints of subjects are accurately represented.
- Data quality checks and cross validation can be helpful; for example, when collecting European and American formatted dates that are presented chronologically, confirm that the months follow as expected to ensure that the dates were interpreted by the data entry staff as expected.
- Data standardization rules need to be employed early on and staff should be trained in proper processes.
Data precision on the other hand can be improved with thorough checks and re-verification. For example:
- Standard Operating Procedures (SOP) need to be established for the process of collection, cleaning, and validation of data.
- Setting and following guidelines to accept data only if it falls within a set bandwidth. For example, heights of children within 16-17 years of age must fall within the range of 4’10” to 6”. Any readings outside of this range can be treated as an outlier and removed from the study.
- Quality check review by multiple parties to spot errors.
- Cleaning of data to take out any duplications or outliers.
- Re-verifying all data to avoid conversion or calculation errors.
Data quality and data integrity are the building blocks of any analysis needed for making decisions. It is important to gather sample data from a wide set of diverse and representative populations and confirm that it is both accurate and precise. Know the difference between accuracy and precision and conform to both, as bad sample data will lead to inaccurate or biased results.
